I have been poking around perl’s internals in my quest to help perl see interesting characters in names and values of environment variables. The first step was to translate the UTF-16 environment which wmain received to a UTF-8 encoded one. The next step will be to ensure that the relevant parts of the code know about this. This requires a small change in mg.c and a much more significant change in hv.c (I must admit, I had not realized until now most of Perl’s hash functionality existed in a single 600 line function). The mechanics of the changes are not that hard, but this made me realize something which I thought was interesting. So, this post is not part of the N-part trilogy of adding Unicode support to perl on the Windows command line.
The reason I ended up at this point is that I realized I would have to deal with the ENV_IS_CASELESS code in hv.c. The code uses strupr to make all environment variables upper case on platforms like Windows where environment variables are case insensitive. A small problem with this is the fact that the Windows environment is case preserving since XP. I do remember some people used this fact to detect whether their programs were running under Windows 9x or XP, but I don’t think that technique is something to be relied on.
Upon realizing I would have to deal with casing issues, the first thing that popped in to my head was the question of how any code I wrote or changed would deal with the Turkish I problem. In a nutshell, the Turkish alphabet has two ’I’s. We have the dotless ı whose upper case version is I and the dotted i whose upper case version is İ. If you are given an i, you don’t know whether to map that to I or İ without knowing if it is used in Turkish or another language. Similarly, given an I, you don’t know whether the lower case version of that is i or ı without knowing if it is used in Turkish. There are two cases without ambiguity: If you have an İ the lower case of that is unambiguously i and if you have an ı, the upper case of that is unambiquously I.
However, very few environments do any of this correctly, so I gave up on things like Turkish characters in file names many decades ago, and I haven’t looked back. This is the one situation I really have to think hard about this because if making perl Unicode aware on the Windows command line is going to break anything that uses the environment, then the effort is not worth it.
So, I went experimenting.
On a modern Windows 10 machine (with OS code page set to 437), here is what I observe:
$ set iş=kârlı
$ echo %iş%
kârlı
$ echo %İŞ%
%İŞ%
$ echo %IŞ%
kârlıwhich makes sense. Now, let’s start out with upper case İ:
$ set İş=kârlı
$ echo %iş%
%iş%
$ echo %ış%
%ış%
$ echo %İŞ%
kârlıThat doesn’t make so much sense. I am not sure what cmd.exe does in the background, but it is probably using something like CharUpperBuff:
Note that CharUpperBuff always maps lowercase I (“i”) to uppercase I, even when the current language is Turkish or Azeri.
or
LCMapString which supposedly maps i to İ if the current language is Turkish or Azeri. I can’t test this on a computer with a Turkish locale because I am unwilling to deal with any unintended consequences of using anything other than the U.S. English locale.
Regardless of which function Windows uses, I don’t see why mapping İ to i presents a problem. Update: Of course, the problem is that when I set İş in the environment and ask for the value of %iş%, Windows upper-cases the i in %iş% to I because I am not working in a Turkish locale. Duh!
This made me curious about how perl and perl6 deal with case transformations of Turkish İ and ı. To abstract away from any issues having to do with cmd.exe, I wrote the simplest script I can run using both interpreters:
print lc( 'İ' ), "\n";
print uc( lc 'İ' ), "\n";
print lc( uc 'ı'), "\n";I also changed my code page to 65001 (UTF-8) in the cmd.exe window I was going to use to run these experiments.
$ perl -Mutf8 -CS t.pl
i̇
İ
iNow, gvim displays lc( 'İ' ) as something that looks like i, but cmd.exe showed this:
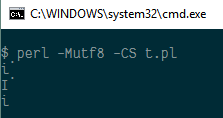
Let’s look at what octets are produced:
$ perl -Mutf8 -CS t.pl |xxd
00000000: 69cc 870d 0a49 cc87 0d0a 690d 0a i....I....i..That’s curious. That is i followed by another Unicode character. What is that?
print charnames::viacode( ord(lc 'İ') ), "\n";
LATIN SMALL LETTER IThat did not reveal much, did it?
Without further ado, Unicode code point \x307 is COMBINING DOT ABOVE. This means perl can preserve the identity 'İ' ≡ uc( lc 'İ' ).
Let’s look at the output I get from perl6 running the same script:
$ perl6 t.pl|xxd
00000000: 69cc 870d 0ac4 b00d 0a69 0d0a i........i..Again, lc( 'İ' ) becomes i followed by COMBINING DOT ABOVE which means uc(lc 'İ') becomes LATIN CAPITAL LETTER I WITH DOT ABOVE as a by product of the fact that perl6 deals in graphemes, which is a good thing:
say 'İ' eq 'İ'.lc.uc.lc.uc;
TrueWell, that’s neither here or there, but I thought it was rather clever to map lc( 'İ' ) to i followed by “combining dot above” so that 'İ' ≡ uc( lc 'İ' ) still held.
I am wondering if there is another codepoint that means something like “no diacritic above” but looking at Wikipedia’s combining characters, I do not see anything that could be useful.
Is there way within the Unicode specification of preserving the identity 'ı' ≡ lc( uc 'ı' )?
PS: You can discuss this post on r/perl.